Case Study
Conversational AI through SMS
How I broke down a problem where repetitive questions from among potentially 10,000 conversations per day, could be identified and responded to autonomously, at scale, and real-time, potentially saving each leasing agent 1 to 1.5 hours per day.
Role: Product owner and strategist, lead designer, data scientist, NLP researcher, ML/Python engineer
Premise
Reva is a B2B2C startup based in Silicon Valley, that makes data-conscious CRM software for the multi-family real estate domain. For its multiple customers, Reva's product helps leasing agents at properties with bringing in leads through various marketing channels and maturing them from contact to contract, and helps property managers with actionable insights through a comprehensive analytics dashboard.
Goals and objectives
Leasing agents at properties respond to multiple leads coming in per day, over multiple channels, and usually, also handle other work like conducting tours, managing maintenance requests, responding to resident concerns, and helping create a feeling of community.
Because of this environment of persistent context switching (an avg. loss of 23 minutes spent realigning focus), a leasing agent could lose about 1 to 1.5 hours a day (even by conservative estimates). It was then in the best interests of both leasing agents and property managers, that a leasing agent can focus on work that they're best equipped to do, while some form of AI autonomously handles repetitive conversational inquiries about inventory availability and booking appointments.
Even by a very conservative Fermi guesstimate (40 agents across 50 properties each losing 1 to 1.5 hours per day), a rigorous automation solution becomes not just a tacked-on value-add, but a necessity.
We first looked at deploying conversational AI through SMS (this case study) and through webchat.
Business, product, and design considerations
Conversational AI once deployed in production would only give us a trained, but unmonitored guess as to what the consumer saying. To ensure the quality of data, we designed a review pipeline to extract conversations from production, and funnel them into training and test sets for a new model. Only a model that outperforms the current model in production, would be served through this continuous improvement/deployment process.
We designed a fallback system where utterances too complex for the bot would be handed to a human agent to resolve. If the bot misclassifies a large number of utterances instead of falling back to a human agent (false negative), the agents would then need to then spend a lot of time cleaning up after the bot. Because this would quickly erode value for both agents and consumers, we designed the system to keep false negatives to a minimum, even if it resulted in a slight increase in the number of false positives (falling back to a human agent when it could have provided the correct response).

Description: Because of the nature of the use cases (available inventory and appointments), our metrics for the pilot started with a conservative estimate of 5 minutes spent per utterance, not including the context switching (because it became extremely complicated to model, with very limited returns) - these metrics would need to be more nuanced once we saw the bot in action. On average, for every 100 utterances, we wanted the bot to confidently classify 32 utterances, while limiting the errors to less than 20. A net gain of 12 successful utterances out of every 100 may not seem like a lot; but this was the bare minimum we wanted to start with, to see if we could really get tangible business value out of implementing conversational AI.
We intuited that how consumers talk to properties tends to stay more or less similar, while the reason the bot needs to be different is how each customer responds to their leads - which we separated into a service containing customer-specific business logic. This decoupling of the understanding and responding components of the bot let us build AI in a more scalable way, as opposed to building and training a different bot for each customer.
Outcome and results
I built a version of conversational AI in Python (with about 300 production utterances) to quickly grok the capabilities and limitations of our chosen tool. This version can communicate with a consumer over text, look for available inventory, and book appointments through Reva's APIs, as well as negotiate the appointment date and time with the consumer. The Reva product and engineering teams plan to extend the work completed here into the next generation architecture that will make the bot even more reliable and extensible.
The baseline model, trained on 6000 annotated utterances from production, performed very close to our expectations, while limiting most misclassifications to a low severity rating. I also wrote node scripts to manage, manipulate, and analyze the large amount of data through spreadsheets.

Description: I set out on making two kinds of models. The 'premonth' model contains training examples from an entire calendar month (August 2020 for this image) before the date of the test set. The 'preday' model is the premonth model plus examples from the test set from the previous date. Both types of models are run against the same test set. This is to primarily understand two things - 1. how drastically the performance of the bot changes based on examples from a single day (answer: better, but only by a little bit) so that we can look to estimate the training set's best possible performance and 2. if any one day's examples create a sharp increase in performance (answer: not really). While we never really hit the 80% mark that we set out to, there's a case for optimism as explained in the next set of charts. I created these handy auto-updating charts in Google Sheets where I was dumping the metrics run from daily trainings and tests. Quite a bit of grunt work, and I'll lament at great length in a blog post.
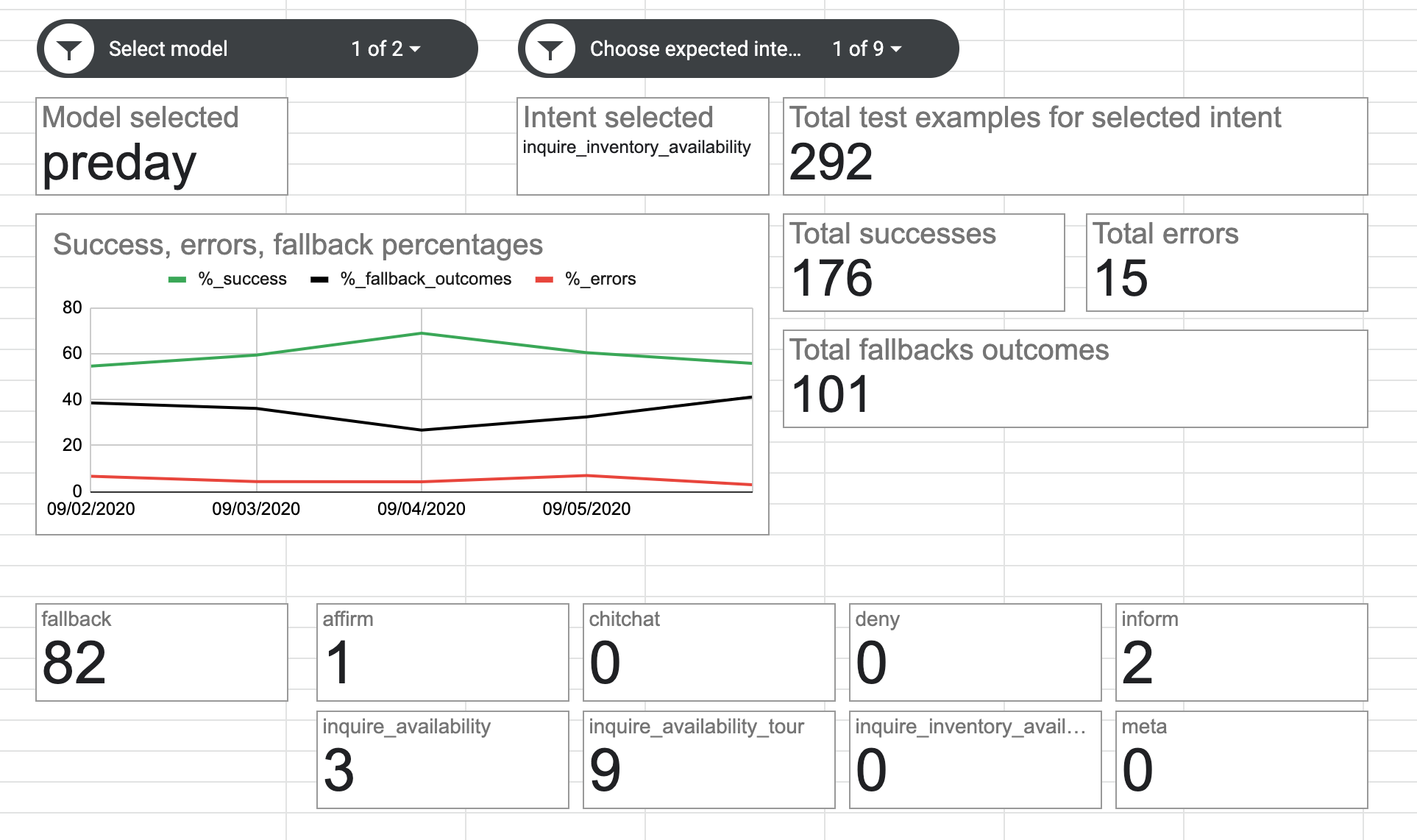
Description: By running training and tests over a number of days, I was able to get metrics down to each specific intent and analyze what it was most confused with. For the intent of inquiring about available inventory, it was confused most with asking to schedule a tour (9 out of 292 test utterances) - however, this isn't a dealbreaker per se. That's when we realized an important nuance that's missing in most conversational AI tools - that not all misclassifications are of equal severity. Also note that there were 101 fallback outcomes while only 82 times, the intent was "incorrectly" identified as fallback. The reason is there were 19 test utterances for which the bot did not guess with high enough confidence. Also for this intent, 34% that we expected the bot to understand, instead had a fallback outcome. Not necessarily a bad outcome, considering that the errors were few in number and of low severity.

Description: For inquiring availability of tours, despite only correctly understanding roughly 50% of the expected test utterances, the bot made only 3 errors of zero-to-low severity. Note that there are two intents here - inquire_availability and inquire_availability_tour. This is to help the bot understand the difference between utterances like "Are you free at 11am on Saturday?" and "Are you free to show me the place Saturday at 11?". For the former, the history till-date of the lead can be used to deduce if the lead is asking about a tour or about a move-in appointment or she's a resident looking to meet the leasing agent doubling up as a community manager.
Team credits
Significant contributions to this project were by Josh Hall (VP of Product) and Christophe Gillette (VP of Engineering) - whose technical inputs on how to build scalable and manageable systems were invaluable. Because Josh and Christophe are two of the best in the business at identifying edge cases, this helped making the design of the system more robust, and its trade-offs more intentional.
Massive credit also to David Straus (CEO) whose inputs guided the vision and direction for the product and its impact upon Reva's customers.
For the first version, I had help from the engineering team to integrate the demo into the core product as well as to add some advanced functions.